Metadata Parsing
Given the simplicity of the format, it’s very simple and efficient to fetch and parse metadata about Safetensors weights – i.e. the list of tensors, their types, and their shapes or numbers of parameters – using small (Range) HTTP requests.
This parsing has been implemented in JS in huggingface.js (sample code follows below), but it would be similar in any language.
Example use case
There can be many potential use cases. For instance, we use it on the Model Database Hub to display info about models which have safetensors weights:
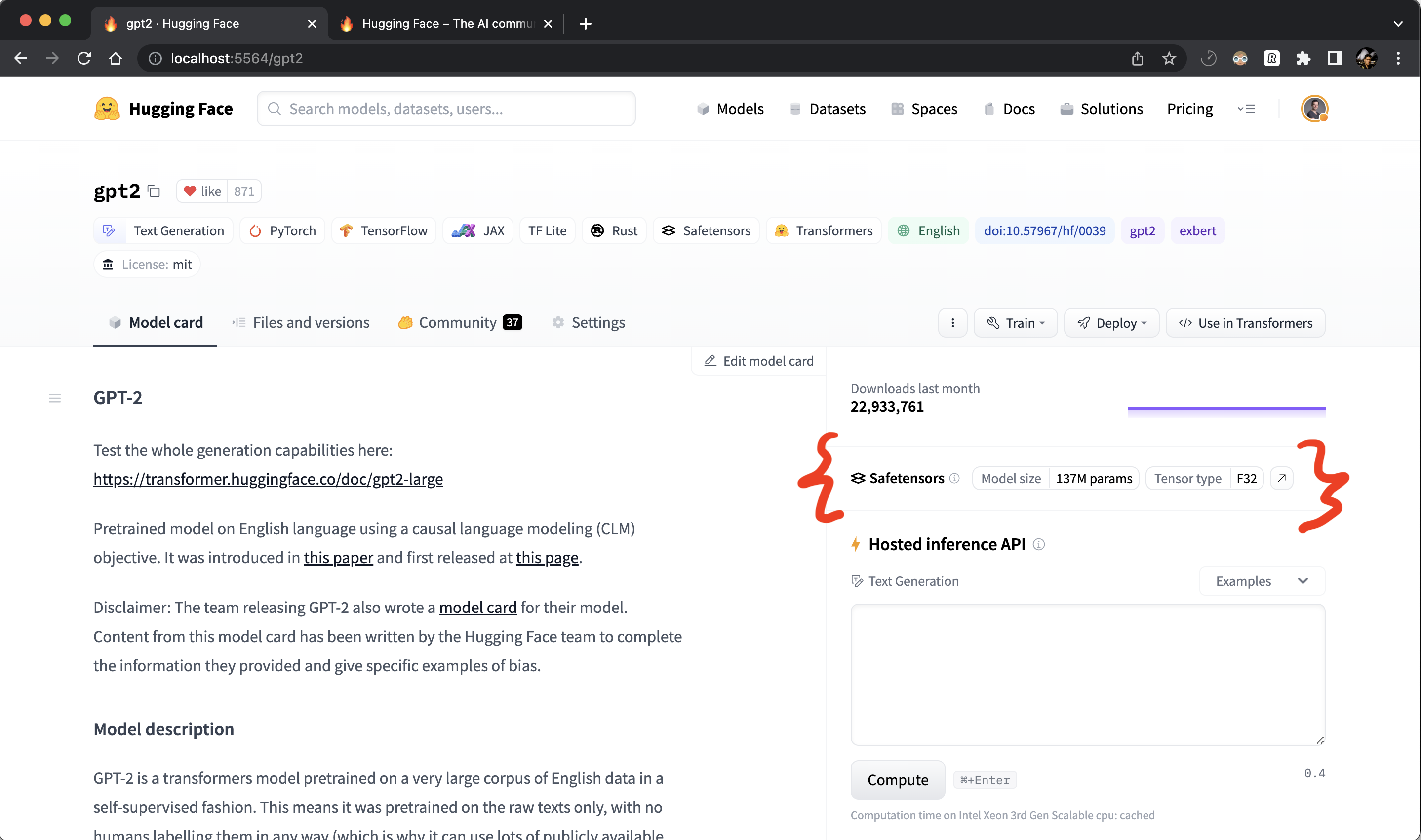



Usage
JavaScript/TypeScript
Using huggingface.js
import { parseSafetensorsMetadata } from "@huggingface/hub";
const info = await parseSafetensorsMetadata({
repo: { type: "model", name: "bigscience/bloom" },
});
console.log(info)
// {
// sharded: true,
// index: {
// metadata: { total_size: 352494542848 },
// weight_map: {
// 'h.0.input_layernorm.bias': 'model_00002-of-00072.safetensors',
// ...
// }
// },
// headers: {
// __metadata__: {'format': 'pt'},
// 'h.2.attn.c_attn.weight': {'dtype': 'F32', 'shape': [768, 2304], 'data_offsets': [541012992, 548090880]},
// ...
// }
// }Depending on whether the safetensors weights are sharded into multiple files or not, the output of the call above will be:
export type SafetensorsParseFromRepo =
| {
sharded: false;
header: SafetensorsFileHeader;
}
| {
sharded: true;
index: SafetensorsIndexJson;
headers: SafetensorsShardedHeaders;
};where the underlying types are the following:
type FileName = string;
type TensorName = string;
type Dtype = "F64" | "F32" | "F16" | "BF16" | "I64" | "I32" | "I16" | "I8" | "U8" | "BOOL";
interface TensorInfo {
dtype: Dtype;
shape: number[];
data_offsets: [number, number];
}
type SafetensorsFileHeader = Record<TensorName, TensorInfo> & {
__metadata__: Record<string, string>;
};
interface SafetensorsIndexJson {
weight_map: Record<TensorName, FileName>;
}
export type SafetensorsShardedHeaders = Record<FileName, SafetensorsFileHeader>;
Python
In this example python script, we are parsing metadata of gpt2.
import requests # pip install requests
import struct
def parse_single_file(url):
# Fetch the first 8 bytes of the file
headers = {'Range': 'bytes=0-7'}
response = requests.get(url, headers=headers)
# Interpret the bytes as a little-endian unsigned 64-bit integer
length_of_header = struct.unpack('<Q', response.content)[0]
# Fetch length_of_header bytes starting from the 9th byte
headers = {'Range': f'bytes=8-{7 + length_of_header}'}
response = requests.get(url, headers=headers)
# Interpret the response as a JSON object
header = response.json()
return header
url = "https://huggingface.co/gpt2/resolve/main/model.safetensors"
header = parse_single_file(url)
print(header)
# {
# "__metadata__": { "format": "pt" },
# "h.10.ln_1.weight": {
# "dtype": "F32",
# "shape": [768],
# "data_offsets": [223154176, 223157248]
# },
# ...
# }Example output
For instance, here are the number of params per dtype for a few models on the Model Database Hub. Also see this issue for more examples of usage.
| model | safetensors | params |
|---|---|---|
| gpt2 | single-file | { ‘F32’ => 137022720 } |
| roberta-base | single-file | { ‘F32’ => 124697433, ‘I64’ => 514 } |
| Jean-Baptiste/camembert-ner | single-file | { ‘F32’ => 110035205, ‘I64’ => 514 } |
| roberta-large | single-file | { ‘F32’ => 355412057, ‘I64’ => 514 } |
| distilbert-base-german-cased | single-file | { ‘F32’ => 67431550 } |
| EleutherAI/gpt-neox-20b | sharded | { ‘F16’ => 20554568208, ‘U8’ => 184549376 } |
| bigscience/bloom-560m | single-file | { ‘F16’ => 559214592 } |
| bigscience/bloom | sharded | { ‘BF16’ => 176247271424 } |
| bigscience/bloom-3b | single-file | { ‘F16’ => 3002557440 } |