Model Details: DPT-Large
Dense Prediction Transformer (DPT) model trained on 1.4 million images for monocular depth estimation.
It was introduced in the paper Vision Transformers for Dense Prediction by Ranftl et al. (2021) and first released in this repository.
DPT uses the Vision Transformer (ViT) as backbone and adds a neck + head on top for monocular depth estimation.
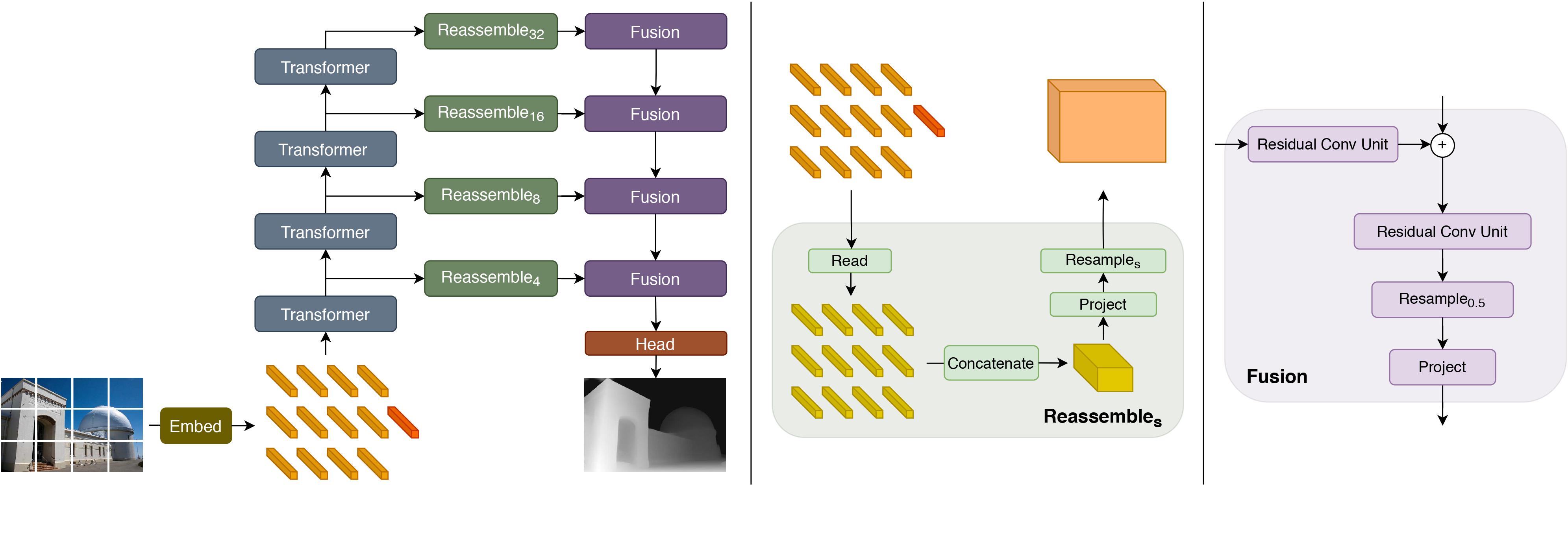
The model card has been written in combination by the Model Database team and Intel.
| Intended Use |
Description |
| Primary intended uses |
You can use the raw model for zero-shot monocular depth estimation. See the model hub to look for fine-tuned versions on a task that interests you. |
| Primary intended users |
Anyone doing monocular depth estimation |
| Out-of-scope uses |
This model in most cases will need to be fine-tuned for your particular task. The model should not be used to intentionally create hostile or alienating environments for people. |
How to use
Here is how to use this model for zero-shot depth estimation on an image:
from transformers import DPTImageProcessor, DPTForDepthEstimation
import torch
import numpy as np
from PIL import Image
import requests
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
processor = DPTImageProcessor.from_pretrained("Intel/dpt-large")
model = DPTForDepthEstimation.from_pretrained("Intel/dpt-large")
inputs = processor(images=image, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs)
predicted_depth = outputs.predicted_depth
prediction = torch.nn.functional.interpolate(
predicted_depth.unsqueeze(1),
size=image.size[::-1],
mode="bicubic",
align_corners=False,
)
output = prediction.squeeze().cpu().numpy()
formatted = (output * 255 / np.max(output)).astype("uint8")
depth = Image.fromarray(formatted)
For more code examples, we refer to the documentation.
| Factors |
Description |
| Groups |
Multiple datasets compiled together |
| Instrumentation |
- |
| Environment |
Inference completed on Intel Xeon Platinum 8280 CPU @ 2.70GHz with 8 physical cores and an NVIDIA RTX 2080 GPU. |
| Card Prompts |
Model deployment on alternate hardware and software will change model performance |
| Metrics |
Description |
| Model performance measures |
Zero-shot Transfer |
| Decision thresholds |
- |
| Approaches to uncertainty and variability |
- |
| Training and Evaluation Data |
Description |
| Datasets |
The dataset is called MIX 6, and contains around 1.4M images. The model was initialized with ImageNet-pretrained weights. |
| Motivation |
To build a robust monocular depth prediction network |
| Preprocessing |
"We resize the image such that the longer side is 384 pixels and train on random square crops of size 384. ... We perform random horizontal flips for data augmentation." See Ranftl et al. (2021) for more details. |
Quantitative Analyses
| Model |
Training set |
DIW WHDR |
ETH3D AbsRel |
Sintel AbsRel |
KITTI δ>1.25 |
NYU δ>1.25 |
TUM δ>1.25 |
| DPT - Large |
MIX 6 |
10.82 (-13.2%) |
0.089 (-31.2%) |
0.270 (-17.5%) |
8.46 (-64.6%) |
8.32 (-12.9%) |
9.97 (-30.3%) |
| DPT - Hybrid |
MIX 6 |
11.06 (-11.2%) |
0.093 (-27.6%) |
0.274 (-16.2%) |
11.56 (-51.6%) |
8.69 (-9.0%) |
10.89 (-23.2%) |
| MiDaS |
MIX 6 |
12.95 (+3.9%) |
0.116 (-10.5%) |
0.329 (+0.5%) |
16.08 (-32.7%) |
8.71 (-8.8%) |
12.51 (-12.5%) |
| MiDaS [30] |
MIX 5 |
12.46 |
0.129 |
0.327 |
23.90 |
9.55 |
14.29 |
| Li [22] |
MD [22] |
23.15 |
0.181 |
0.385 |
36.29 |
27.52 |
29.54 |
| Li [21] |
MC [21] |
26.52 |
0.183 |
0.405 |
47.94 |
18.57 |
17.71 |
| Wang [40] |
WS [40] |
19.09 |
0.205 |
0.390 |
31.92 |
29.57 |
20.18 |
| Xian [45] |
RW [45] |
14.59 |
0.186 |
0.422 |
34.08 |
27.00 |
25.02 |
| Casser [5] |
CS [8] |
32.80 |
0.235 |
0.422 |
21.15 |
39.58 |
37.18 |
Table 1. Comparison to the state of the art on monocular depth estimation. We evaluate zero-shot cross-dataset transfer according to the
protocol defined in [30]. Relative performance is computed with respect to the original MiDaS model [30]. Lower is better for all metrics. (Ranftl et al., 2021)
| Ethical Considerations |
Description |
| Data |
The training data come from multiple image datasets compiled together. |
| Human life |
The model is not intended to inform decisions central to human life or flourishing. It is an aggregated set of monocular depth image datasets. |
| Mitigations |
No additional risk mitigation strategies were considered during model development. |
| Risks and harms |
The extent of the risks involved by using the model remain unknown. |
| Use cases |
- |
| Caveats and Recommendations |
| Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. There are no additional caveats or recommendations for this model. |
BibTeX entry and citation info
@article{DBLP:journals/corr/abs-2103-13413,
author = {Ren{\'{e}} Ranftl and
Alexey Bochkovskiy and
Vladlen Koltun},
title = {Vision Transformers for Dense Prediction},
journal = {CoRR},
volume = {abs/2103.13413},
year = {2021},
url = {https://arxiv.org/abs/2103.13413},
eprinttype = {arXiv},
eprint = {2103.13413},
timestamp = {Wed, 07 Apr 2021 15:31:46 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-2103-13413.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
