Posts, articles, and discussions

Community posts

Deploy MusicGen in no time with Inference Endpoints
By August 4, 2023

Fine-tuning MMS Adapter Models for Multi-Lingual ASR
By June 19, 2023

Speech Synthesis, Recognition, and More With SpeechT5
By February 8, 2023

A Complete Guide to Audio Datasets
By December 15, 2022

Fine-Tune Whisper with 🤗 Transformers
By November 3, 2022

Introducing new audio and vision documentation in 🤗 Datasets
By July 28, 2022

Putting ethical principles at the core of research lifecycle
By May 19, 2022

Making automatic speech recognition work on large files with Wav2Vec2 in 🤗 Transformers
By February 1, 2022

Boost Wav2Vec2 with n-gram LM in 🤗 Transformers
By January 12, 2022

Perceiver IO: a scalable, fully-attentional model that works on any modality
By December 15, 2021
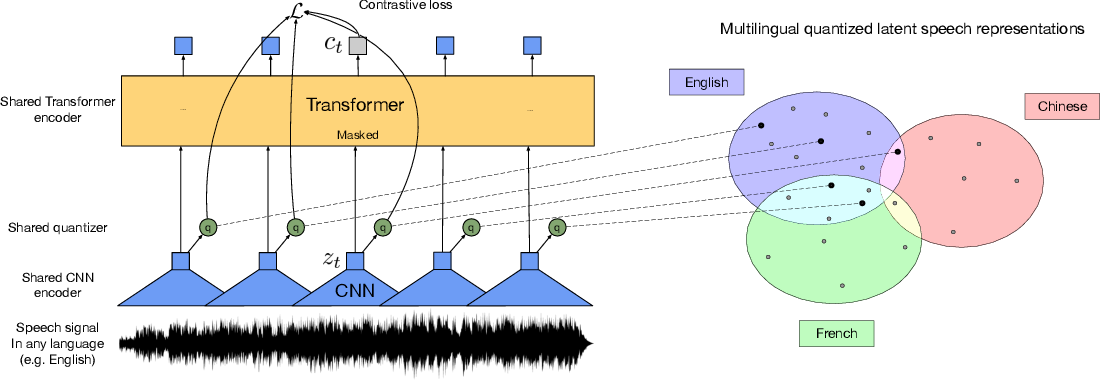
Fine-tuning XLS-R for Multi-Lingual ASR with 🤗 Transformers
By November 15, 2021
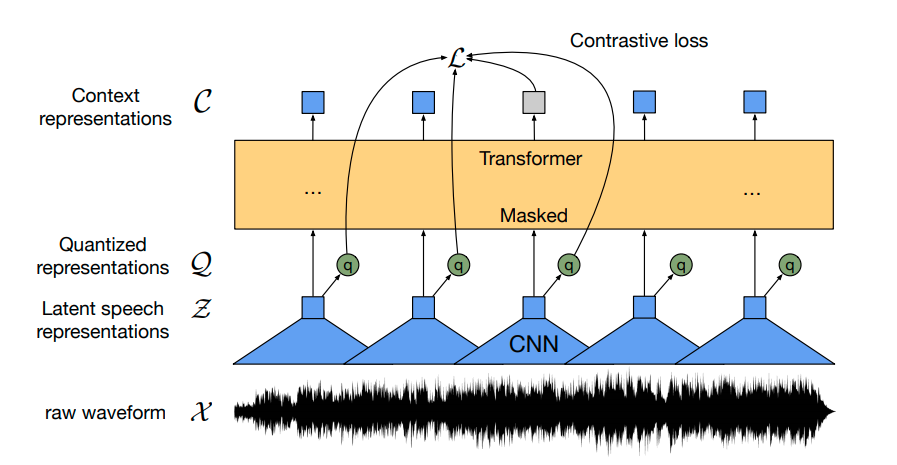
Fine-Tune Wav2Vec2 for English ASR with 🤗 Transformers
By March 12, 2021