
HF Repo •🐱 Github Repo • 🐦 Twitter • 📃 [WizardLM] • 📃 [WizardCoder] • 📃 [WizardMath]
👋 Join our Discord
News
- 🔥🔥🔥[2023/08/26] We released WizardCoder-Python-34B-V1.0 , which achieves the 73.2 pass@1 and surpasses GPT4 (2023/03/15), ChatGPT-3.5, and Claude2 on the HumanEval Benchmarks.
- [2023/06/16] We released WizardCoder-15B-V1.0 , which achieves the 57.3 pass@1 and surpasses Claude-Plus (+6.8), Bard (+15.3) and InstructCodeT5+ (+22.3) on the HumanEval Benchmarks.
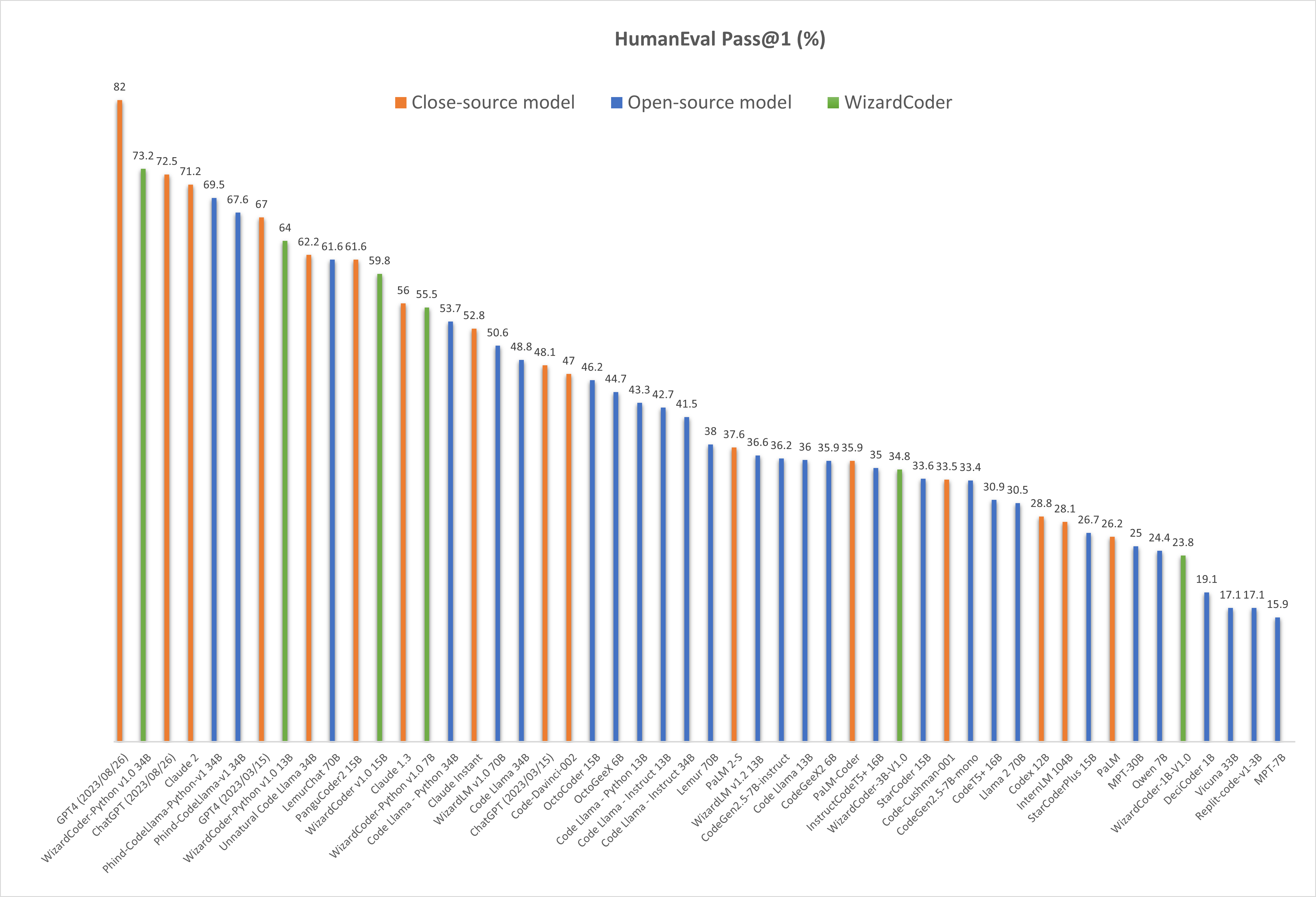
❗Note: There are two HumanEval results of GPT4 and ChatGPT-3.5. The 67.0 and 48.1 are reported by the official GPT4 Report (2023/03/15) of OpenAI. The 82.0 and 72.5 are tested by ourselves with the latest API (2023/08/26).
| Model | Checkpoint | Paper | HumanEval | MBPP | Demo | License |
|---|---|---|---|---|---|---|
| WizardCoder-Python-34B-V1.0 | HF Link | 📃 [WizardCoder] | 73.2 | 61.2 | Demo | Llama2 |
| WizardCoder-15B-V1.0 | HF Link | 📃 [WizardCoder] | 59.8 | 50.6 | -- | OpenRAIL-M |
| WizardCoder-Python-13B-V1.0 | HF Link | 📃 [WizardCoder] | 64.0 | 55.6 | -- | Llama2 |
| WizardCoder-3B-V1.0 | HF Link | 📃 [WizardCoder] | 34.8 | 37.4 | Demo | OpenRAIL-M |
| WizardCoder-1B-V1.0 | HF Link | 📃 [WizardCoder] | 23.8 | 28.6 | -- | OpenRAIL-M |
- Our WizardMath-70B-V1.0 model slightly outperforms some closed-source LLMs on the GSM8K, including ChatGPT 3.5, Claude Instant 1 and PaLM 2 540B.
- Our WizardMath-70B-V1.0 model achieves 81.6 pass@1 on the GSM8k Benchmarks, which is 24.8 points higher than the SOTA open-source LLM, and achieves 22.7 pass@1 on the MATH Benchmarks, which is 9.2 points higher than the SOTA open-source LLM.
| Model | Checkpoint | Paper | GSM8k | MATH | Online Demo | License |
|---|---|---|---|---|---|---|
| WizardMath-70B-V1.0 | HF Link | 📃 [WizardMath] | 81.6 | 22.7 | Demo | Llama 2 |
| WizardMath-13B-V1.0 | HF Link | 📃 [WizardMath] | 63.9 | 14.0 | Demo | Llama 2 |
| WizardMath-7B-V1.0 | HF Link | 📃 [WizardMath] | 54.9 | 10.7 | Demo | Llama 2 |
- [08/09/2023] We released WizardLM-70B-V1.0 model. Here is Full Model Weight.
| Model | Checkpoint | Paper | MT-Bench | AlpacaEval | GSM8k | HumanEval | License |
|---|---|---|---|---|---|---|---|
| WizardLM-70B-V1.0 | HF Link | 📃Coming Soon | 7.78 | 92.91% | 77.6% | 50.6 | Llama 2 License |
| WizardLM-13B-V1.2 | HF Link | 7.06 | 89.17% | 55.3% | 36.6 | Llama 2 License | |
| WizardLM-13B-V1.1 | HF Link | 6.76 | 86.32% | 25.0 | Non-commercial | ||
| WizardLM-30B-V1.0 | HF Link | 7.01 | 37.8 | Non-commercial | |||
| WizardLM-13B-V1.0 | HF Link | 6.35 | 75.31% | 24.0 | Non-commercial | ||
| WizardLM-7B-V1.0 | HF Link | 📃 [WizardLM] | 19.1 | Non-commercial | |||
Comparing WizardCoder-Python-34B-V1.0 with Other LLMs.
🔥 The following figure shows that our WizardCoder-Python-34B-V1.0 attains the second position in this benchmark, surpassing GPT4 (2023/03/15, 73.2 vs. 67.0), ChatGPT-3.5 (73.2 vs. 72.5) and Claude2 (73.2 vs. 71.2).
Prompt Format
"Below is an instruction that describes a task. Write a response that appropriately completes the request.\n\n### Instruction:\n{instruction}\n\n### Response:"
Inference Demo Script
We provide the inference demo code here.
Citation
Please cite the repo if you use the data, method or code in this repo.
@article{luo2023wizardcoder,
title={WizardCoder: Empowering Code Large Language Models with Evol-Instruct},
author={Luo, Ziyang and Xu, Can and Zhao, Pu and Sun, Qingfeng and Geng, Xiubo and Hu, Wenxiang and Tao, Chongyang and Ma, Jing and Lin, Qingwei and Jiang, Daxin},
journal={arXiv preprint arXiv:2306.08568},
year={2023}
}
- Downloads last month
- 34,887