Spread Your Wings: Falcon 180B is here





Introduction
Today, we're excited to welcome TII's Falcon 180B to HuggingFace! Falcon 180B sets a new state-of-the-art for open models. It is the largest openly available language model, with 180 billion parameters, and was trained on a massive 3.5 trillion tokens using TII's RefinedWeb dataset. This represents the longest single-epoch pretraining for an open model.
You can find the model on the Model Database Hub (base and chat model) and interact with the model on the Falcon Chat Demo Space.
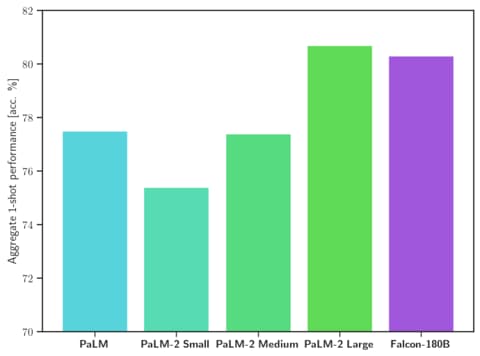
In terms of capabilities, Falcon 180B achieves state-of-the-art results across natural language tasks. It tops the leaderboard for (pre-trained) open-access models and rivals proprietary models like PaLM-2. While difficult to rank definitively yet, it is considered on par with PaLM-2 Large, making Falcon 180B one of the most capable LLMs publicly known.
In this blog post, we explore what makes Falcon 180B so good by looking at some evaluation results and show how you can use the model.
What is Falcon-180B?
Falcon 180B is a model released by TII that follows previous releases in the Falcon family.
Architecture-wise, Falcon 180B is a scaled-up version of Falcon 40B and builds on its innovations such as multiquery attention for improved scalability. We recommend reviewing the initial blog post introducing Falcon to dive into the architecture. Falcon 180B was trained on 3.5 trillion tokens on up to 4096 GPUs simultaneously, using Amazon SageMaker for a total of ~7,000,000 GPU hours. This means Falcon 180B is 2.5 times larger than Llama 2 and was trained with 4x more compute.
The dataset for Falcon 180B consists predominantly of web data from RefinedWeb (~85%). In addition, it has been trained on a mix of curated data such as conversations, technical papers, and a small fraction of code (~3%). This pretraining dataset is big enough that even 3.5 trillion tokens constitute less than an epoch.
The released chat model is fine-tuned on chat and instruction datasets with a mix of several large-scale conversational datasets.
‼️ Commercial use: Falcon 180b can be commercially used but under very restrictive conditions, excluding any "hosting use". We recommend to check the license and consult your legal team if you are interested in using it for commercial purposes.
How good is Falcon 180B?
Falcon 180B is the best openly released LLM today, outperforming Llama 2 70B and OpenAI’s GPT-3.5 on MMLU, and is on par with Google's PaLM 2-Large on HellaSwag, LAMBADA, WebQuestions, Winogrande, PIQA, ARC, BoolQ, CB, COPA, RTE, WiC, WSC, ReCoRD. Falcon 180B typically sits somewhere between GPT 3.5 and GPT4 depending on the evaluation benchmark and further finetuning from the community will be very interesting to follow now that it's openly released.
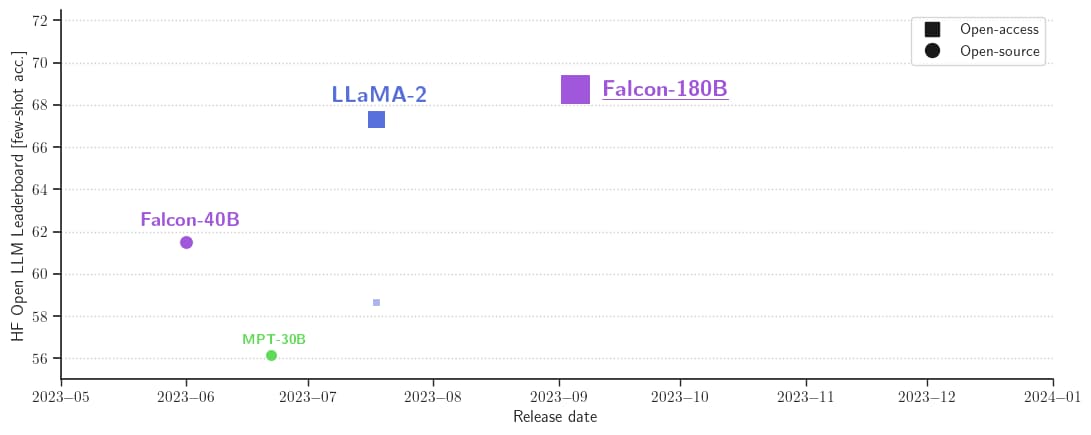
With 68.74 on the Model Database Leaderboard, Falcon 180B is the highest-scoring openly released pre-trained LLM, surpassing Meta’s LLaMA 2 (67.35).
| Model | Size | Leaderboard score | Commercial use or license | Pretraining length |
|---|---|---|---|---|
| Falcon | 180B | 68.74 | 🟠 | 3,500B |
| Llama 2 | 70B | 67.35 | 🟠 | 2,000B |
| LLaMA | 65B | 64.23 | 🔴 | 1,400B |
| Falcon | 40B | 61.48 | 🟢 | 1,000B |
| MPT | 30B | 56.15 | 🟢 | 1,000B |
The quantized Falcon models preserve similar metrics across benchmarks. The results were similar when evaluating torch.float16, 8bit, and 4bit. See results in the Open LLM Leaderboard.
How to use Falcon 180B?
Falcon 180B is available in the Model Database ecosystem, starting with Transformers version 4.33.
Demo
You can easily try the Big Falcon Model (180 billion parameters!) in this Space or in the playground embedded below:
Hardware requirements
We ran several tests on the hardware needed to run the model for different use cases. Those are not the minimum numbers, but the minimum numbers for the configurations we had access to.
| Type | Kind | Memory | Example | |
|---|---|---|---|---|
| Falcon 180B | Training | Full fine-tuning | 5120GB | 8x 8x A100 80GB |
| Falcon 180B | Training | LoRA with ZeRO-3 | 1280GB | 2x 8x A100 80GB |
| Falcon 180B | Training | QLoRA | 160GB | 2x A100 80GB |
| Falcon 180B | Inference | BF16/FP16 | 640GB | 8x A100 80GB |
| Falcon 180B | Inference | GPTQ/int4 | 320GB | 8x A100 40GB |
Prompt format
The base model has no prompt format. Remember that it’s not a conversational model or trained with instructions, so don’t expect it to generate conversational responses—the pretrained model is a great platform for further finetuning, but you probably shouldn’t driectly use it out of the box. The Chat model has a very simple conversation structure.
System: Add an optional system prompt here
User: This is the user input
Falcon: This is what the model generates
User: This might be a second turn input
Falcon: and so on
Transformers
With the release of Transformers 4.33, you can use Falcon 180B and leverage all the tools in the HF ecosystem, such as:
- training and inference scripts and examples
- safe file format (safetensors)
- integrations with tools such as bitsandbytes (4-bit quantization), PEFT (parameter efficient fine-tuning) and GPTQ
- assisted generation (also known as “speculative decoding”)
- RoPE scaling support for larger context lengths
- rich and powerful generation parameters
Use of the model requires you to accept its license and terms of use. Please, make sure you are logged into your Model Database account and ensure you have the latest version of transformers:
pip install --upgrade transformers
huggingface-cli login
bfloat16
This is how you’d use the base model in bfloat16. Falcon 180B is a big model, so please take into account the hardware requirements summarized in the table above.
from transformers import AutoTokenizer, AutoModelForCausalLM
import transformers
import torch
model_id = "tiiuae/falcon-180B"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
device_map="auto",
)
prompt = "My name is Pedro, I live in"
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
output = model.generate(
input_ids=inputs["input_ids"],
attention_mask=inputs["attention_mask"],
do_sample=True,
temperature=0.6,
top_p=0.9,
max_new_tokens=50,
)
output = output[0].to("cpu")
print(tokenizer.decode(output)
This could produce an output such as:
My name is Pedro, I live in Portugal and I am 25 years old. I am a graphic designer, but I am also passionate about photography and video.
I love to travel and I am always looking for new adventures. I love to meet new people and explore new places.
8-bit and 4-bit with bitsandbytes
The 8-bit and 4-bit quantized versions of Falcon 180B show almost no difference in evaluation with respect to the bfloat16 reference! This is very good news for inference, as you can confidently use a quantized version to reduce hardware requirements. Keep in mind, though, that 8-bit inference is much faster than running the model in 4-bit.
To use quantization, you need to install the bitsandbytes library and simply enable the corresponding flag when loading the model:
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
load_in_8bit=True,
device_map="auto",
)
Chat Model
As mentioned above, the version of the model fine-tuned to follow conversations used a very straightforward training template. We have to follow the same pattern in order to run chat-style inference. For reference, you can take a look at the format_prompt function in the Chat demo, which looks like this:
def format_prompt(message, history, system_prompt):
prompt = ""
if system_prompt:
prompt += f"System: {system_prompt}\n"
for user_prompt, bot_response in history:
prompt += f"User: {user_prompt}\n"
prompt += f"Falcon: {bot_response}\n"
prompt += f"User: {message}\nFalcon:"
return prompt
As you can see, interactions from the user and responses by the model are preceded by User: and Falcon: separators. We concatenate them together to form a prompt containing the conversation's whole history. We can provide a system prompt to tweak the generation style.
Additional Resources
Acknowledgments
Releasing such a model with support and evaluations in the ecosystem would not be possible without the contributions of many community members, including Clémentine and Eleuther Evaluation Harness for LLM evaluations; Loubna and BigCode for code evaluations; Nicolas for Inference support; Lysandre, Matt, Daniel, Amy, Joao, and Arthur for integrating Falcon into transformers. Thanks to Baptiste and Patrick for the open-source demo. Thanks to Thom, Lewis, TheBloke, Nouamane, Tim Dettmers for multiple contributions enabling this to get out. Finally, thanks to the HF Cluster for enabling running LLM evaluations as well as providing inference for a free, open-source demo of the model.

